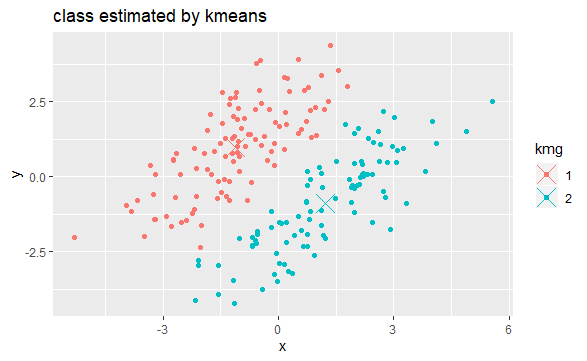
\(k\) -means 방법 \(k\) – means 방법은 다변량 자료를 클러스터링을 하는 가장 대표적인 방법이다. 개념은 간단하다. \(k\) 개의 평균이 있고, 이 평균은 모두 서로 다른 집단을 나타낸다. 모든 자료는 가장 가까운 평균에 소속된다. 가우시안 혼합 모형(GMM: Gaussian Mixture Model) 1변수 두 집단의 가우시안 혼합 모형은 다음과 같다. \[f(X=x|\mu_1, \sigma_1, \mu_2, \sigma_2) = w_1\frac{1}{\sigma_1\sqrt{2\pi}}\exp\left[-\frac{1}{2}(\frac{x-\mu_1}{\sigma_1})^2\right] + w_2\frac{1}{\sigma_2\sqrt{2\pi}}\exp\left[-\frac{1}{2}(\frac{x-\mu_2}{\sigma_2})^2\right]\] … k-means와 GMM 비교 계속 읽기
0 댓글